Николай Варанкин - Исследовательский проект "Multiplying Table LLM"
Русский
English
中文
Кратко
Проекты
Контакты
Обо мне
Новости
LinkedIn™
Quora™
Publications
Positional encoding is rather an accidental requirement
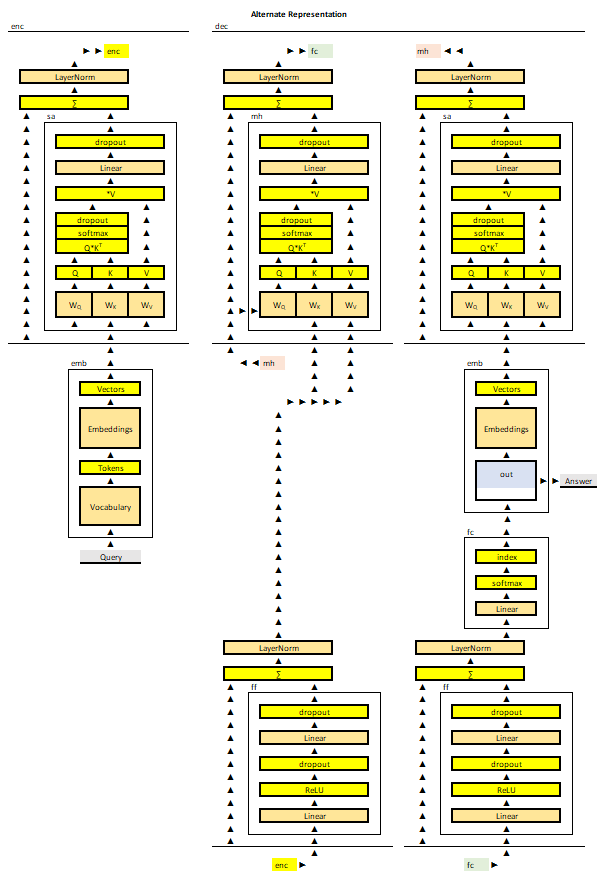
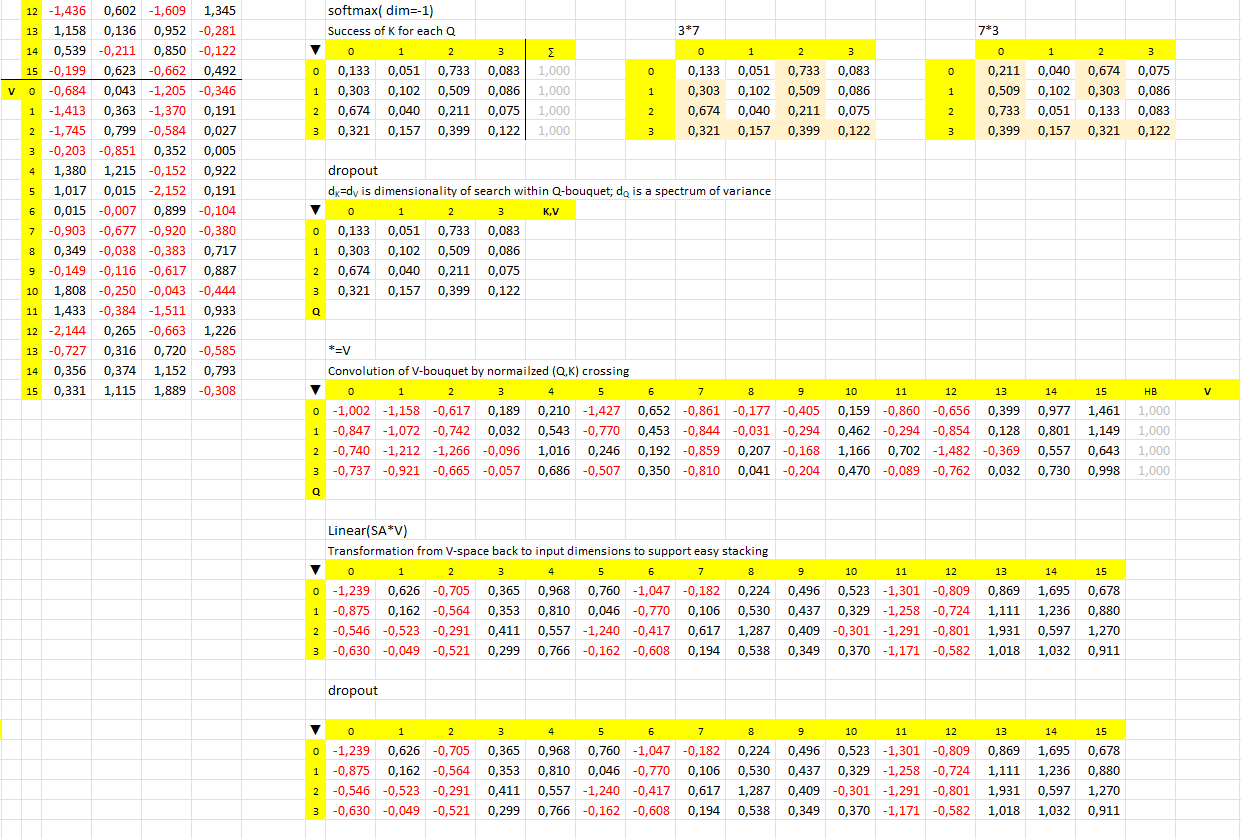
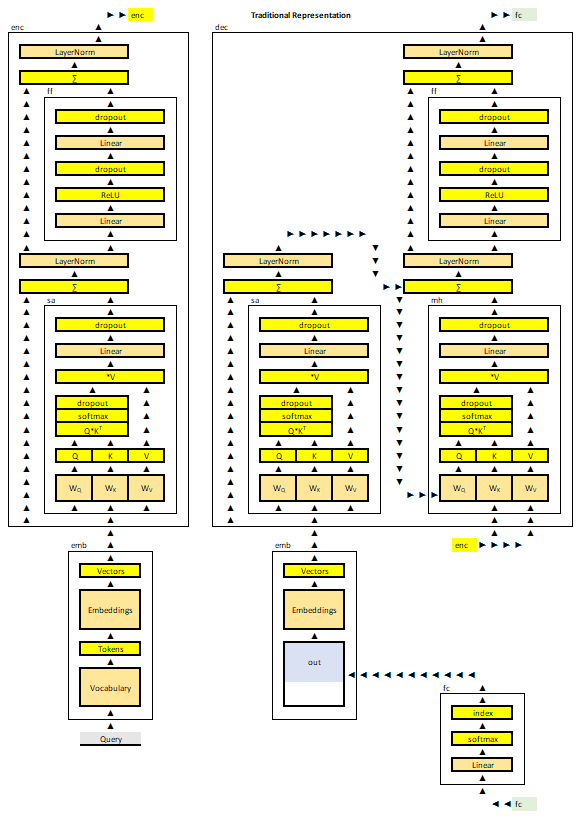
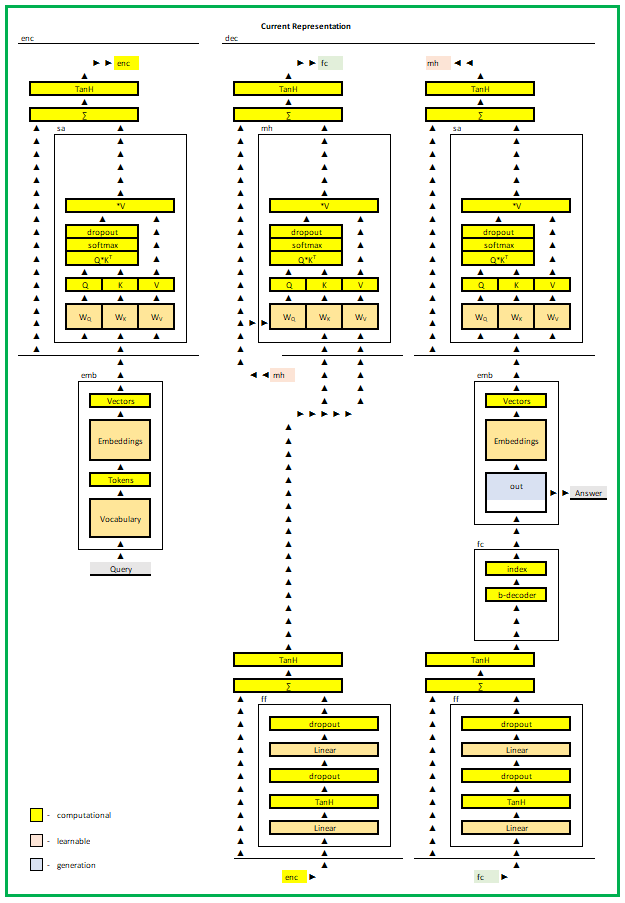
What is internal logic behind the LLM pipeline of tensors?
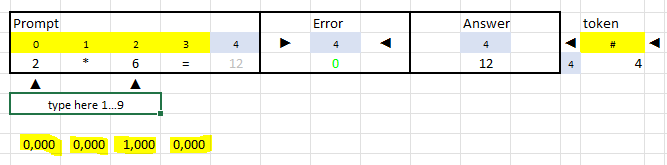
If anybody wants to learn LLM by hand - AI and ML Community
Here's untold story about latent matrix space
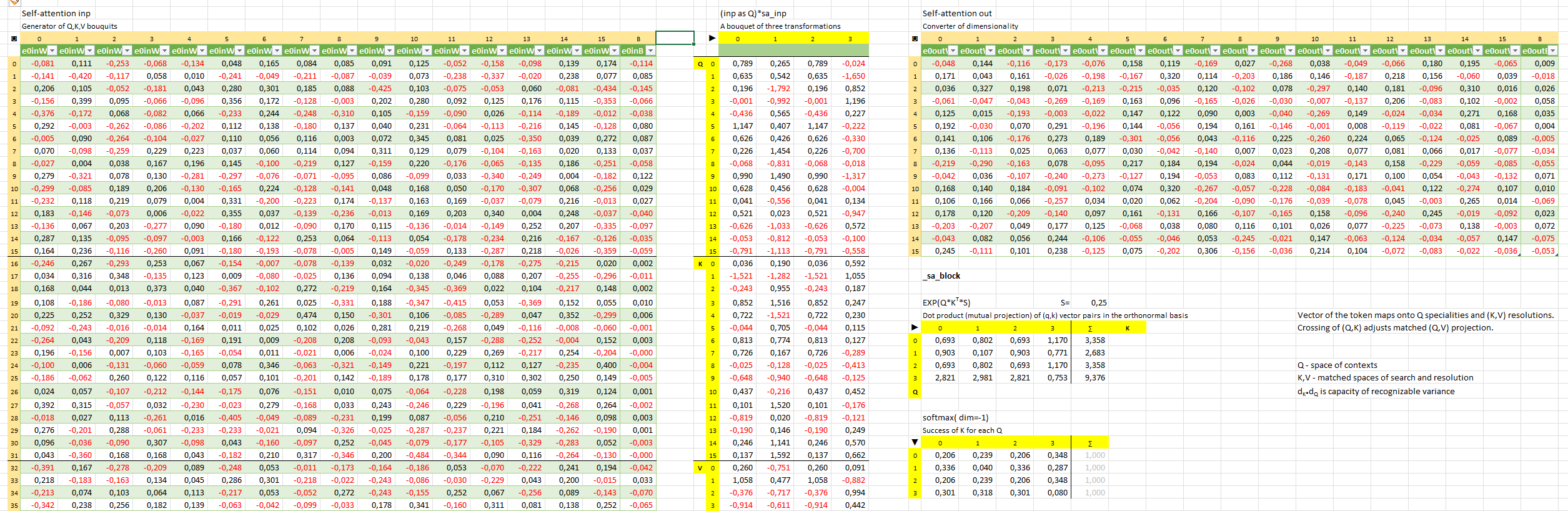
I've found logic predicates in the LLM self-attention!
What is happening inside?
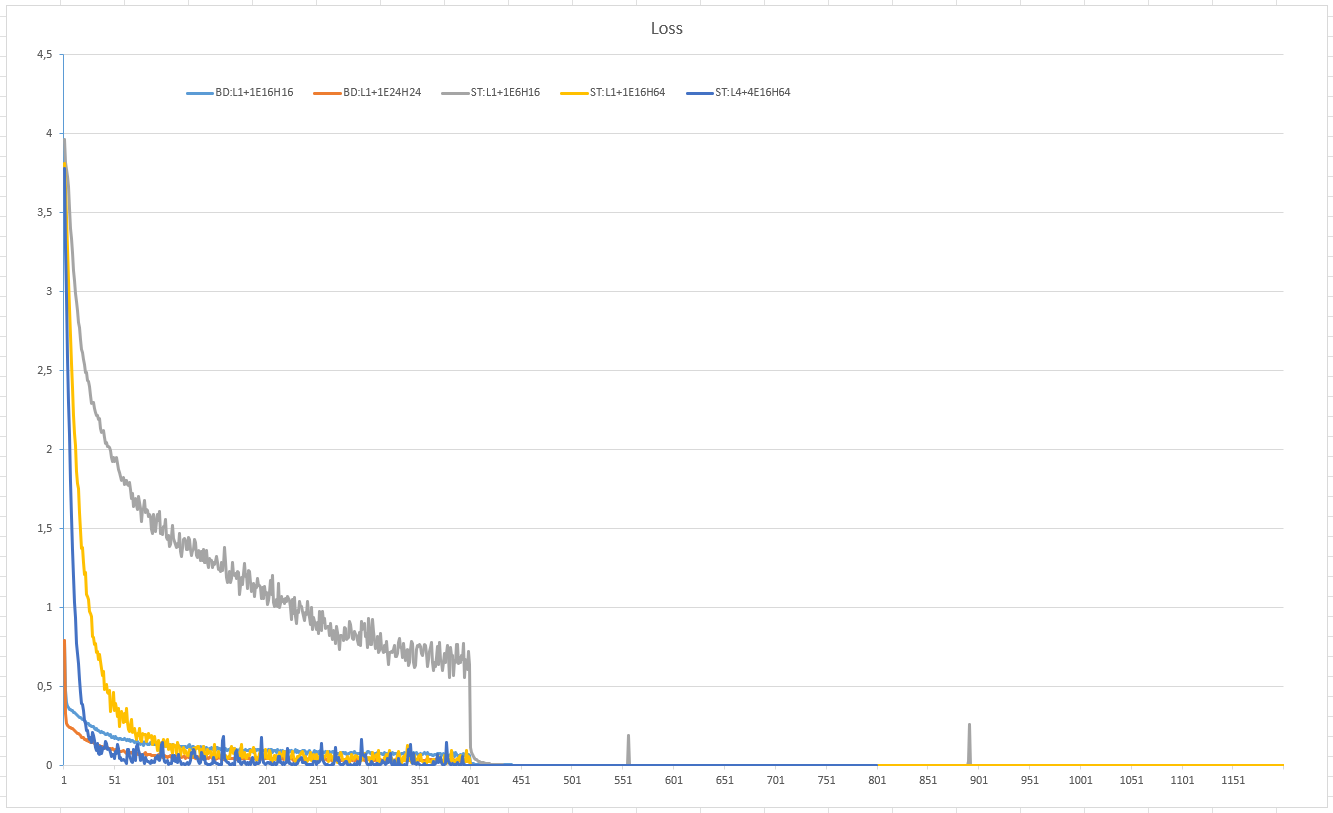
Digging the model loss in a mirror of the training process
My Transformer research is available in the public domain
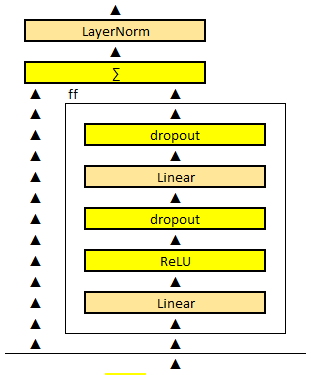
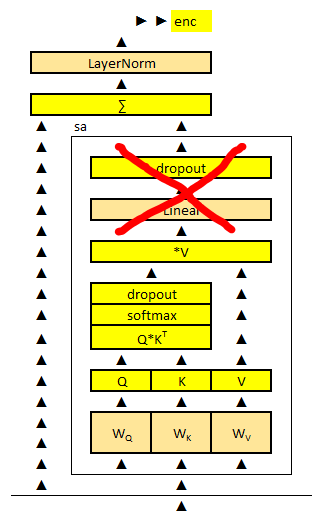
How many redundant parts are there in a Transformer?
The whole Transformer Series
How small LLM can be?
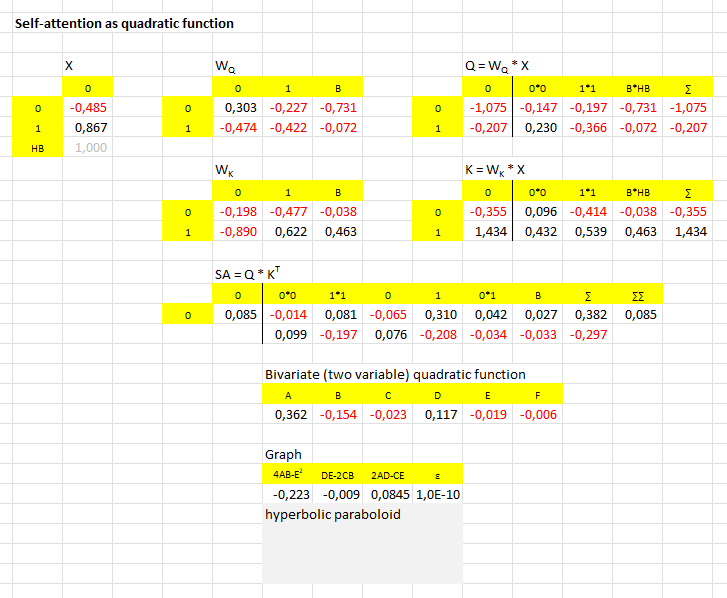
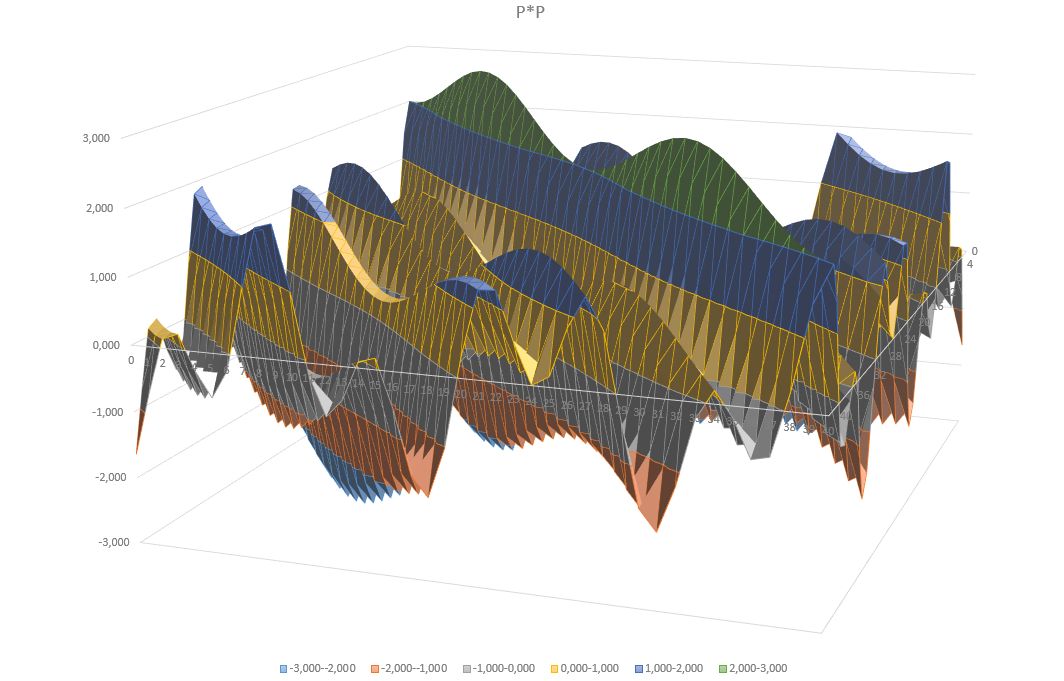
Two-faced mathematics - is it real?
How to check validity of global model parameters of LLM
Self-attention in the architecture of transformer holds a mystery
Neural nets grew up from trivial Frank Rosenblatt's fully connected layers
What is this thing for?
Midnight talks with LLM
What language does LLM speak?
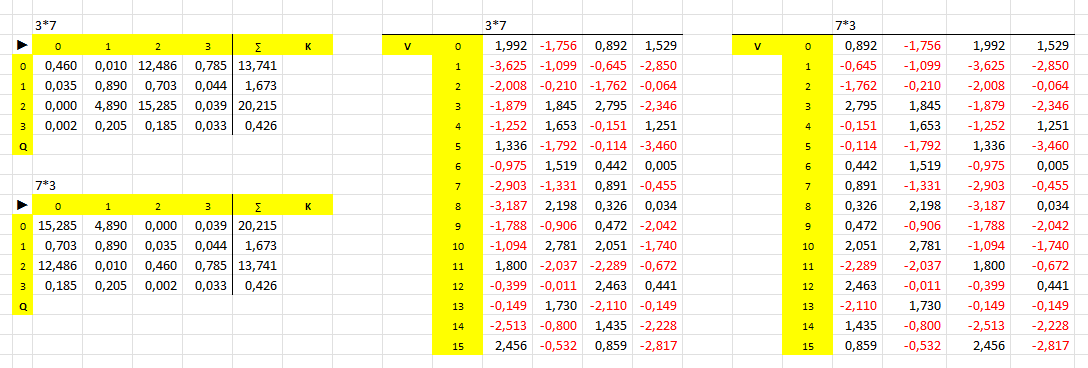
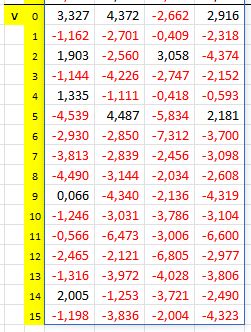
Apply hard scrutiny to find out hidden relationships between raw numbers
Life with fully connected layers is full of computational surprises
I've put the project on the GitHub under MIT license
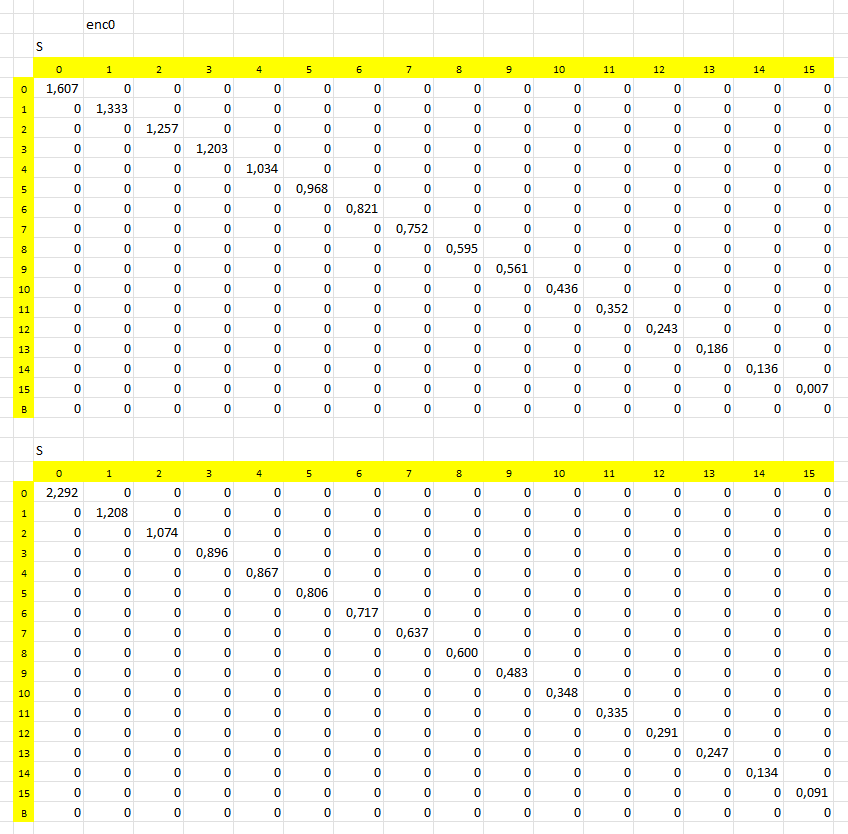
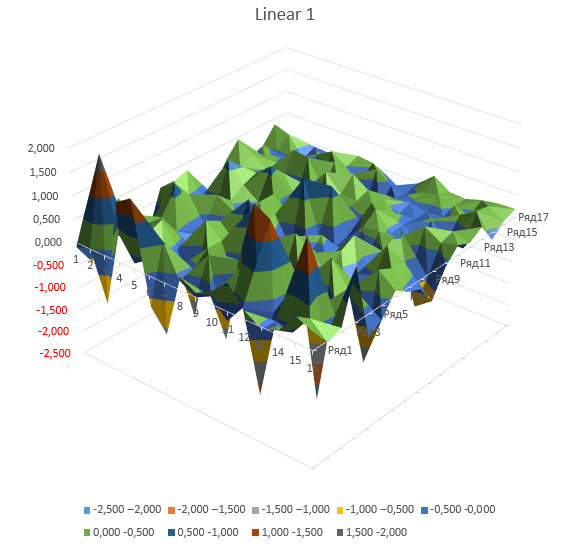
Graphs of self-crossing for positional embeddings
I decided to learn LLM by hand
I've got a clear understanding of why a Transformer can comprehend
To be continued...
To be continued...
To be continued...
To be continued...
To be continued...
© Image credit to all 3
rd
party artworks has been expressed in linked publications.
Разделы
Программный код
Публикации


.PNG)

.PNG)